In previous posts, we demonstrated the use of natural language processing (“NLP”) for authorship attribution in connection with the anonymous author of an op-ed and book criticizing Donald Trump. Now Anonymous has revealed himself as Miles Taylor, former Chief of Staff at the Department of Homeland Security (“DHS”). This affords an opportunity to test the validity of the NLP authorship attribution approach described in the prior posts, albeit limited by the paucity of Taylor’s public writings.
To recapitulate, NLP analyzes speech characteristics such as sentence length, punctuation and word-type frequencies. In assessing two earlier possible Anonymous identities, I compared several characteristics of their attributed book writings with those of Anonymous:
- Words per sentence, mean (average)
- Words per sentence, standard deviation
- Ratio of the number of different words used to the total number of words used (“lexical diversity”)
- Per-sentence numbers of
- Commas
- Colons
- Semicolons
- Singular nouns
- Plural nouns
- Proper nouns, singular
- Determiners
- Prepositions or subordinating conjunctions
- Adjectives
Unlike the previous Anonymous candidates, Tayor has not written any other books, at least not for attribution. He did, however, write an op-ed for the Washington Post in August 2020, which we can compare to his Anonymous op-ed, although this makes thin gruel for authorship attribution. Op-eds may be too short and variable to reveal patterns across any two of them. But it would appear to make little sense to compare an op-ed to a book, given the different demands and characteristics of each.
Indeed, the brevity of the op-eds highlighted an additional NLP problem over which I previously glossed: NLP ’s imperfect identification of parts of speech. In this case, I noticed that the software (Natural Language Toolkit for Python, one of if not the most used NLP program) counted no proper nouns in Taylor’s more recent, for-attribution op-ed—clearly an error and rather an alarming one, given Taylor’s repeated references to himself, Trump, various states and countries, and DHS. The count of a single proper noun in the earlier, Anonymous op-ed also is also clearly wrong. Other, non-zero counting errors would not be so obvious to detect. It may be that the errors, if they occur at the same rate across all texts, balance out over lengthier texts and do not affect the final comparison. It may also be that they throw the entire analysis off: garbage in, garbage out.
As discussed in the previous posts, moreover, NLP analysis generally, and this analysis in particular, suffers from other possible points of failure. For example, Taylor may have deliberately altered his style as Anonymous to obscure his identity. The publications in which the op-eds appear, the Washington Post and New York Times, may edit the articles differently so as to yield different stylistic measurements.
The pitfalls described above should be kept in mind during the discussion which follows.
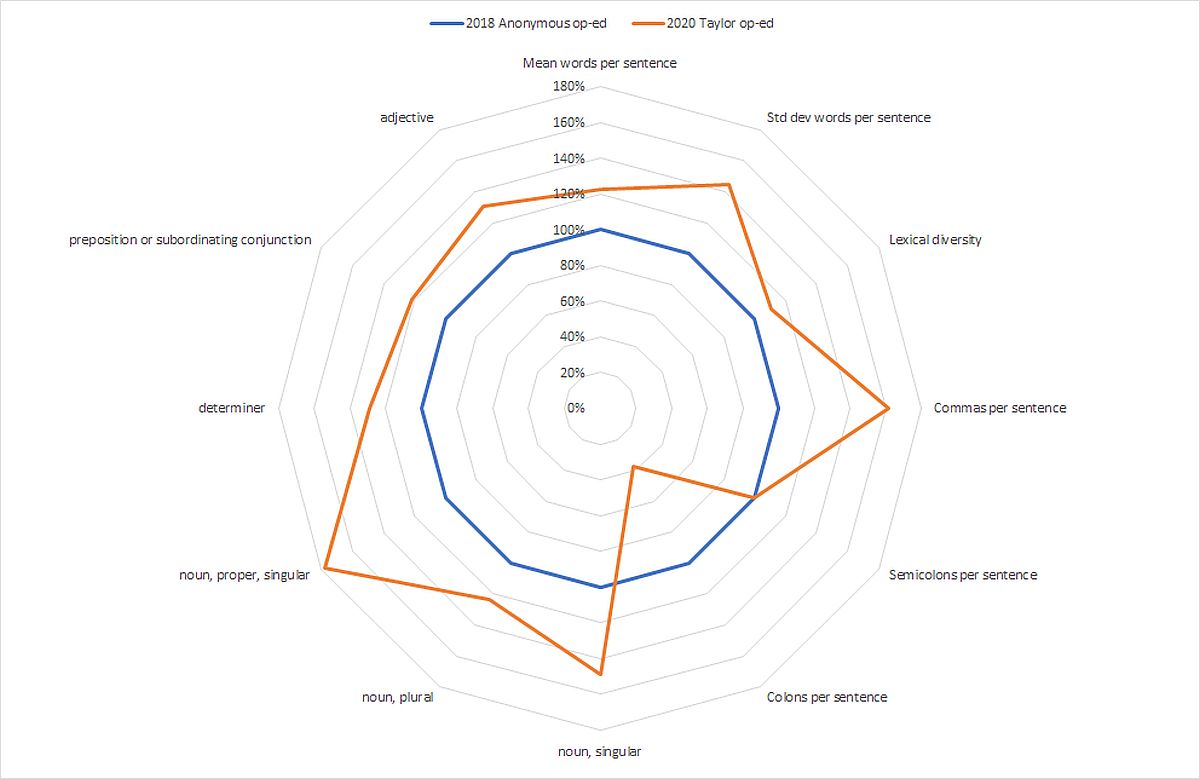
As before, a comparison of twelve traits for Taylor’s Anonymous and attributed op-eds appear in tabular and graphical form below, including the raw data for both publications, as well as the attributed op-ed values expressed as a percentage of the corresponding Anonymous values. My manual count replaces the software’s erroneous proper-noun counting error described above. In addition, I equalized semicolons counts at 100% although the two zero counts technically yield a division error.
| Stylistic Trait | 2018 Anonymous op-ed | 2020 Taylor op-ed | 2020 Taylor as a percentage of 2018 Anonymous |
| Mean words per sentence | 19.7 | 24.15 | 123% |
| Std dev words per sentence | 11.17 | 16.17 | 145% |
| Lexical diversity | 0.48 | 0.53 | 110% |
| Commas per sentence | 0.78 | 1.26 | 162% |
| Semicolons per sentence | 0.0001* | 0.0001* | 100% |
| Colons per sentence | 0.08 | 0.03 | 38% |
| Nouns, singular, per sentence | 3.24 | 4.82 | 149% |
| Nouns, plural, per sentence | 1.26 | 1.56 | 124% |
| Nouns, proper, singular, per sentence | 0.78§ | 1.39§ | 178% |
| Determiners per sentence | 1.84 | 2.38 | 129% |
| Prepositions or subordinating conjunctions per sentence | 2.44 | 2.97 | 122% |
| Adjectives per sentence | 2.1 | 2.74 | 130% |
* Actual count was 0. Set to 0.0001 to avoid division-by-zero error in proportional comparison.
§ Replaced clearly erroneous software counts with manual counts.
As noted in the prior posts, the import of this comparison cannot be ascertained without comparing other potential authors. The analysis is not helpful if the writings of persons known not to be Anonymous—such as earlier “suspects” Snodgrass or Coates—bear a closer resemblance to Anonymous than Taylor himself. In this case, we do not have op-eds from Snodgrass and Coates, but we do have books, which the prior posts compared to Taylor’s anonymous book. The chart below reflects stylistic values for Taylor’s 2020 for-attribution op-ed compared with his 2018 Anonymous op-ed, and for the Snodgrass and Coates books compared with Taylor’s Anonymous book. The raw tabular data is available above and in the most recent previous post on this subject. The chart shows that, apart from semicolons per sentence (in the case of Coates) and colons per sentence (in the case of Snodgrass), their books are closer to Taylor’s Anonymous book than Taylor’s attributed op-ed is to his Anonymous op-ed.
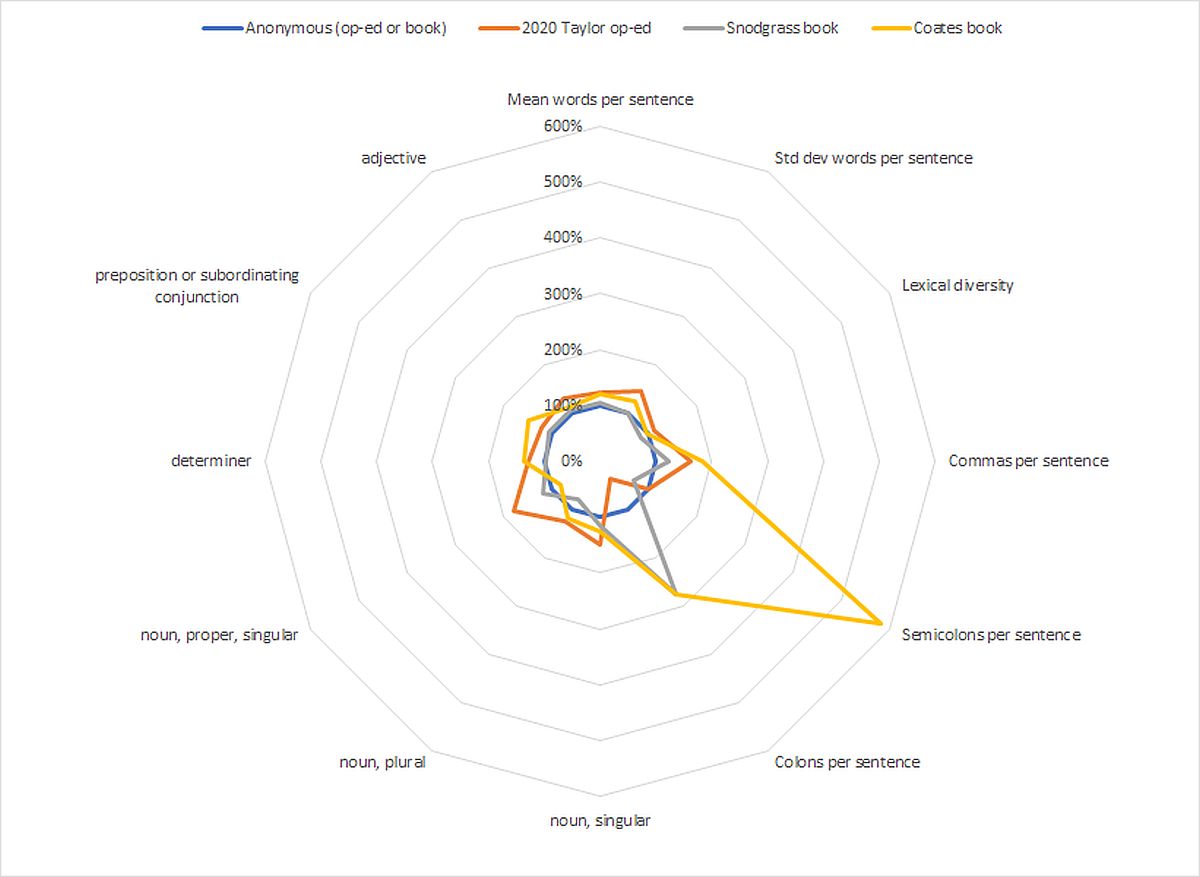
As alluded to above, this comparison is of doubtful probative value given the greater expected variability between shorter op-eds than between books due to much smaller sample sizes. The average figures for numerous op-eds by each author would afford a superior comparison, did they exist. That may form the subject of a future post, given sufficient interest.
For now, however, this NLP file is closed. I hope this exercise has demonstrated some of the possibilities, and pitfalls, of NLP analysis, here in the context of authorship attribution. Other uses include automated translation between different languages, customer-service chat bots, speech recognition, optical character recognition (“OCR”), part-of-speech tagging, named entity recognition, and more.
Please comment below or contact me directly if you have information about NLP software error rates or would be interested in further investigation. I remain interested to know what authorship attribution software the White House used in its pursuit of Anonymous.
Tags: natural language processing, nlp, authorship attribution, machine learning, anonymous, miles taylor
Bruce Ellis Fein, Legal Director and Co-Founder of Dagger Analytics, Inc., leads Dagger’s legal predictive coding operations.